- Home ›
- MySQLの使い方 ›
- MySQLの基本構文
文字セットと照合順序
MySQL ではデータベース、テーブル、カラムのそれぞれに対して文字セットと照合順序を設定することができます。ここでは MySQL における照合順序に関する簡単な説明と文字セット毎に指定可能な照合順序の一覧を確認する方法について解説します。
(Last modified: )
目次
照合順序を選択する
MySQL で指定可能な文字セットの一覧については「MySQLで設定可能な文字セットの一覧」を参照されてください。
一覧の中から一部抜粋すると次のような文字セットがあります。
| Charset | Description | Default collation | Maxlen |
|---|---|---|---|
| binary | Binary pseudo charset | binary | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
MySQL では文字セット毎にデフォルトの照合順序が設定されています。照合順序というのは値を並び替えする時のルールです。大文字と小文字を区別するかどうかやバイナリで比較するかどうかなどです。文字セット毎に複数の照合順序が用意されており、データベースやテーブルを作成する時に文字セットといっしょに照合順序を指定することができます。
データベースなどを作成する時に文字セットだけ指定して照合順序を指定しなかった場合はデフォルトの照合順序が適用されます。デフォルトの照合順序は先ほどの表の Default collation の列に記載されており、例えば文字セットとして utf8mb4 を使用する場合、デフォルトの照合順序は utf8mb4_0900_ai_ci です。
では文字セット毎にどのような照合順序が用意されているかを確認してみます。次のように入力することで取得できます。
show collation where charset = '文字コード';
最初に文字セットが cp932 の場合です。 2 個の照合順序が用意されていました。
show collation where charset = 'cp932';
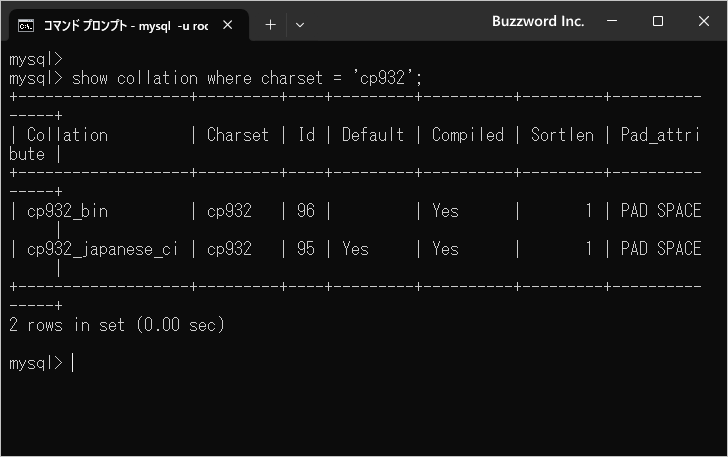
+-------------------+---------+----+---------+----------+---------+---------------+ | Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute | +-------------------+---------+----+---------+----------+---------+---------------+ | cp932_bin | cp932 | 96 | | Yes | 1 | PAD SPACE | | cp932_japanese_ci | cp932 | 95 | Yes | Yes | 1 | PAD SPACE | +-------------------+---------+----+---------+----------+---------+---------------+ 2 rows in set (0.00 sec)
次にに文字セットが utf8mb4 の場合です。 89 個の照合順序が用意されていました。
show collation where charset = 'utf8mb4';
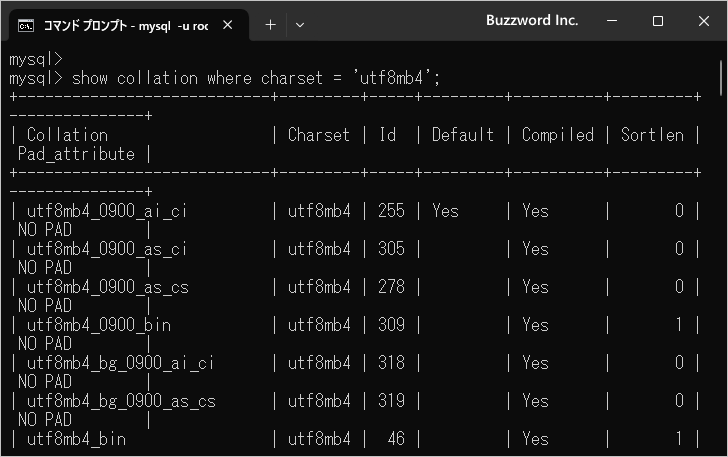
+----------------------------+---------+-----+---------+----------+---------+---------------+ | Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute | +----------------------------+---------+-----+---------+----------+---------+---------------+ | utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD | | utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD | | utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD | | utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD | | utf8mb4_bg_0900_ai_ci | utf8mb4 | 318 | | Yes | 0 | NO PAD | | utf8mb4_bg_0900_as_cs | utf8mb4 | 319 | | Yes | 0 | NO PAD | | utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE | | utf8mb4_bs_0900_ai_ci | utf8mb4 | 316 | | Yes | 0 | NO PAD | | utf8mb4_bs_0900_as_cs | utf8mb4 | 317 | | Yes | 0 | NO PAD | | utf8mb4_croatian_ci | utf8mb4 | 245 | | Yes | 8 | PAD SPACE | | utf8mb4_cs_0900_ai_ci | utf8mb4 | 266 | | Yes | 0 | NO PAD | | utf8mb4_cs_0900_as_cs | utf8mb4 | 289 | | Yes | 0 | NO PAD | | utf8mb4_czech_ci | utf8mb4 | 234 | | Yes | 8 | PAD SPACE | | utf8mb4_danish_ci | utf8mb4 | 235 | | Yes | 8 | PAD SPACE | | utf8mb4_da_0900_ai_ci | utf8mb4 | 267 | | Yes | 0 | NO PAD | | utf8mb4_da_0900_as_cs | utf8mb4 | 290 | | Yes | 0 | NO PAD | | utf8mb4_de_pb_0900_ai_ci | utf8mb4 | 256 | | Yes | 0 | NO PAD | | utf8mb4_de_pb_0900_as_cs | utf8mb4 | 279 | | Yes | 0 | NO PAD | | utf8mb4_eo_0900_ai_ci | utf8mb4 | 273 | | Yes | 0 | NO PAD | | utf8mb4_eo_0900_as_cs | utf8mb4 | 296 | | Yes | 0 | NO PAD | | utf8mb4_esperanto_ci | utf8mb4 | 241 | | Yes | 8 | PAD SPACE | | utf8mb4_estonian_ci | utf8mb4 | 230 | | Yes | 8 | PAD SPACE | | utf8mb4_es_0900_ai_ci | utf8mb4 | 263 | | Yes | 0 | NO PAD | | utf8mb4_es_0900_as_cs | utf8mb4 | 286 | | Yes | 0 | NO PAD | | utf8mb4_es_trad_0900_ai_ci | utf8mb4 | 270 | | Yes | 0 | NO PAD | | utf8mb4_es_trad_0900_as_cs | utf8mb4 | 293 | | Yes | 0 | NO PAD | | utf8mb4_et_0900_ai_ci | utf8mb4 | 262 | | Yes | 0 | NO PAD | | utf8mb4_et_0900_as_cs | utf8mb4 | 285 | | Yes | 0 | NO PAD | | utf8mb4_general_ci | utf8mb4 | 45 | | Yes | 1 | PAD SPACE | | utf8mb4_german2_ci | utf8mb4 | 244 | | Yes | 8 | PAD SPACE | | utf8mb4_gl_0900_ai_ci | utf8mb4 | 320 | | Yes | 0 | NO PAD | | utf8mb4_gl_0900_as_cs | utf8mb4 | 321 | | Yes | 0 | NO PAD | | utf8mb4_hr_0900_ai_ci | utf8mb4 | 275 | | Yes | 0 | NO PAD | | utf8mb4_hr_0900_as_cs | utf8mb4 | 298 | | Yes | 0 | NO PAD | | utf8mb4_hungarian_ci | utf8mb4 | 242 | | Yes | 8 | PAD SPACE | | utf8mb4_hu_0900_ai_ci | utf8mb4 | 274 | | Yes | 0 | NO PAD | | utf8mb4_hu_0900_as_cs | utf8mb4 | 297 | | Yes | 0 | NO PAD | | utf8mb4_icelandic_ci | utf8mb4 | 225 | | Yes | 8 | PAD SPACE | | utf8mb4_is_0900_ai_ci | utf8mb4 | 257 | | Yes | 0 | NO PAD | | utf8mb4_is_0900_as_cs | utf8mb4 | 280 | | Yes | 0 | NO PAD | | utf8mb4_ja_0900_as_cs | utf8mb4 | 303 | | Yes | 0 | NO PAD | | utf8mb4_ja_0900_as_cs_ks | utf8mb4 | 304 | | Yes | 24 | NO PAD | | utf8mb4_latvian_ci | utf8mb4 | 226 | | Yes | 8 | PAD SPACE | | utf8mb4_la_0900_ai_ci | utf8mb4 | 271 | | Yes | 0 | NO PAD | | utf8mb4_la_0900_as_cs | utf8mb4 | 294 | | Yes | 0 | NO PAD | | utf8mb4_lithuanian_ci | utf8mb4 | 236 | | Yes | 8 | PAD SPACE | | utf8mb4_lt_0900_ai_ci | utf8mb4 | 268 | | Yes | 0 | NO PAD | | utf8mb4_lt_0900_as_cs | utf8mb4 | 291 | | Yes | 0 | NO PAD | | utf8mb4_lv_0900_ai_ci | utf8mb4 | 258 | | Yes | 0 | NO PAD | | utf8mb4_lv_0900_as_cs | utf8mb4 | 281 | | Yes | 0 | NO PAD | | utf8mb4_mn_cyrl_0900_ai_ci | utf8mb4 | 322 | | Yes | 0 | NO PAD | | utf8mb4_mn_cyrl_0900_as_cs | utf8mb4 | 323 | | Yes | 0 | NO PAD | | utf8mb4_nb_0900_ai_ci | utf8mb4 | 310 | | Yes | 0 | NO PAD | | utf8mb4_nb_0900_as_cs | utf8mb4 | 311 | | Yes | 0 | NO PAD | | utf8mb4_nn_0900_ai_ci | utf8mb4 | 312 | | Yes | 0 | NO PAD | | utf8mb4_nn_0900_as_cs | utf8mb4 | 313 | | Yes | 0 | NO PAD | | utf8mb4_persian_ci | utf8mb4 | 240 | | Yes | 8 | PAD SPACE | | utf8mb4_pl_0900_ai_ci | utf8mb4 | 261 | | Yes | 0 | NO PAD | | utf8mb4_pl_0900_as_cs | utf8mb4 | 284 | | Yes | 0 | NO PAD | | utf8mb4_polish_ci | utf8mb4 | 229 | | Yes | 8 | PAD SPACE | | utf8mb4_romanian_ci | utf8mb4 | 227 | | Yes | 8 | PAD SPACE | | utf8mb4_roman_ci | utf8mb4 | 239 | | Yes | 8 | PAD SPACE | | utf8mb4_ro_0900_ai_ci | utf8mb4 | 259 | | Yes | 0 | NO PAD | | utf8mb4_ro_0900_as_cs | utf8mb4 | 282 | | Yes | 0 | NO PAD | | utf8mb4_ru_0900_ai_ci | utf8mb4 | 306 | | Yes | 0 | NO PAD | | utf8mb4_ru_0900_as_cs | utf8mb4 | 307 | | Yes | 0 | NO PAD | | utf8mb4_sinhala_ci | utf8mb4 | 243 | | Yes | 8 | PAD SPACE | | utf8mb4_sk_0900_ai_ci | utf8mb4 | 269 | | Yes | 0 | NO PAD | | utf8mb4_sk_0900_as_cs | utf8mb4 | 292 | | Yes | 0 | NO PAD | | utf8mb4_slovak_ci | utf8mb4 | 237 | | Yes | 8 | PAD SPACE | | utf8mb4_slovenian_ci | utf8mb4 | 228 | | Yes | 8 | PAD SPACE | | utf8mb4_sl_0900_ai_ci | utf8mb4 | 260 | | Yes | 0 | NO PAD | | utf8mb4_sl_0900_as_cs | utf8mb4 | 283 | | Yes | 0 | NO PAD | | utf8mb4_spanish2_ci | utf8mb4 | 238 | | Yes | 8 | PAD SPACE | | utf8mb4_spanish_ci | utf8mb4 | 231 | | Yes | 8 | PAD SPACE | | utf8mb4_sr_latn_0900_ai_ci | utf8mb4 | 314 | | Yes | 0 | NO PAD | | utf8mb4_sr_latn_0900_as_cs | utf8mb4 | 315 | | Yes | 0 | NO PAD | | utf8mb4_sv_0900_ai_ci | utf8mb4 | 264 | | Yes | 0 | NO PAD | | utf8mb4_sv_0900_as_cs | utf8mb4 | 287 | | Yes | 0 | NO PAD | | utf8mb4_swedish_ci | utf8mb4 | 232 | | Yes | 8 | PAD SPACE | | utf8mb4_tr_0900_ai_ci | utf8mb4 | 265 | | Yes | 0 | NO PAD | | utf8mb4_tr_0900_as_cs | utf8mb4 | 288 | | Yes | 0 | NO PAD | | utf8mb4_turkish_ci | utf8mb4 | 233 | | Yes | 8 | PAD SPACE | | utf8mb4_unicode_520_ci | utf8mb4 | 246 | | Yes | 8 | PAD SPACE | | utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 8 | PAD SPACE | | utf8mb4_vietnamese_ci | utf8mb4 | 247 | | Yes | 8 | PAD SPACE | | utf8mb4_vi_0900_ai_ci | utf8mb4 | 277 | | Yes | 0 | NO PAD | | utf8mb4_vi_0900_as_cs | utf8mb4 | 300 | | Yes | 0 | NO PAD | | utf8mb4_zh_0900_as_cs | utf8mb4 | 308 | | Yes | 0 | NO PAD | +----------------------------+---------+-----+---------+----------+---------+---------------+ 89 rows in set (0.00 sec)
なお照合順序の末尾に _ci や _bin などが付いていますがそれぞれ次のような意味を持ちます。
_ci 大文字と小文字を区別しない _cs 大文字と小文字を区別する _bin バイナリ比較を行う
目的に合わせて文字セットを選択するときに照合順序もあわせて選択されてください。
-- --
MySQL における照合順序に関する簡単な説明と文字セット毎に指定可能な照合順序の一覧を確認する方法について解説しました。
( Written by Tatsuo Ikura )

著者 / TATSUO IKURA
これから IT 関連の知識を学ばれる方を対象に、色々な言語でのプログラミング方法や関連する技術、開発環境構築などに関する解説サイトを運営しています。