重複データを除外して取得(DISTINCT)
テーブルからデータを取得した時、まったく同じデータが含まれている場合がありますが、 DISTINCT を指定すると重複したデータを除外した上でデータを取得することができます。ここでは SQLite で DISTINCT を使って重複したデータを除外する方法について解説します。
(Last modified: )
DISTINCT を使った重複データの除外
SELECT 文を使ってデータを取得した時に、重複したデータを取り除いてデータを取得するには DISTINCT キーワードを使用します。書式は次の通りです。
SELECT DISTINCT カラム名, ... FROM テーブル名;
重複しているかどうかの判断はデータ全体が一致しているかどうかではなく、データの中で SELECT 文で取得したカラムの値が一致しているデータが対象となります。カラムが1つであればそのカラムの値が同じデータ、複数のカラムの値を取得している場合はその値の組み合わせが全て同じデータが除外対象となります。。
なお DISTINCT とは逆に重複するデータも全て取得する場合には ALL キーワードを指定します。書式は次の通りです。
SELECT ALL カラム名, ... FROM テーブル名;
ただし DISTINCT も ALL も指定しなかった場合は ALL が記述された場合と同じになりますので、特に指定する必要はありません。
----
では実際に試してみます。次のようなテーブルを作成しました。
create table product(id integer, name text, color text);
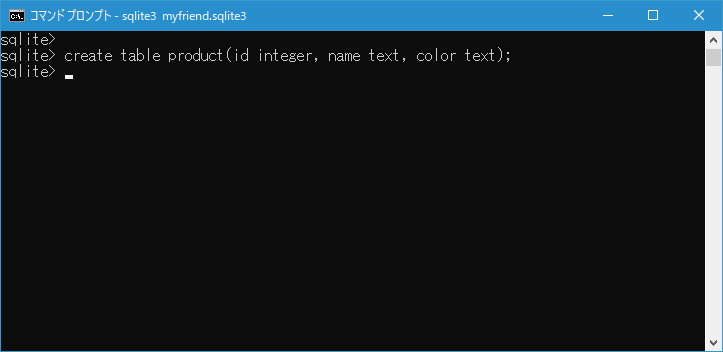
INSERT 文を使ってテーブルにデータをいくつか格納しておきます。
insert into product values(1, 'Mouse', 'White');
insert into product values(2, 'Pen', 'Green');
insert into product values(3, 'Mouse', 'Black');
insert into product values(4, 'NotePC', 'Black');
insert into product values(5, 'Display', 'Yellow');
insert into product values(6, 'Mouse', 'White');
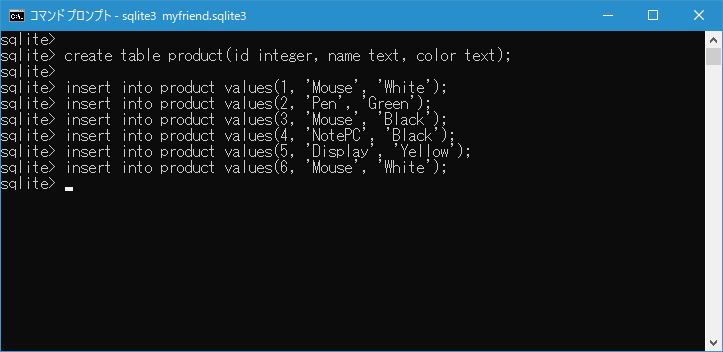
それでは DISTINCT を指定するとどのように変わるのかを確認してみます。最初に product テーブルの name カラムの値を重複したものも含めて取得してみます。
select name from product;
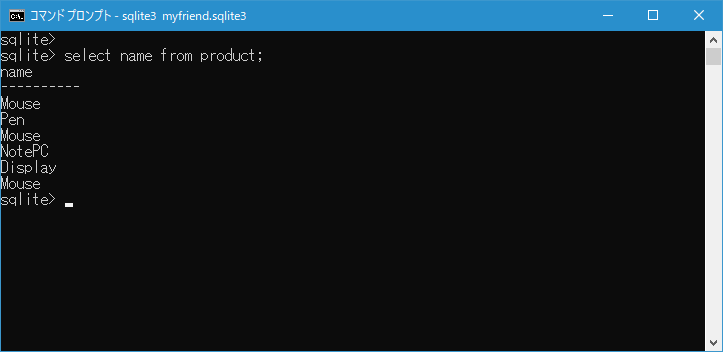
次に DISTINCT キーワードを指定して product テーブルの name カラムの値を取得してみます。
select distinct name from product;
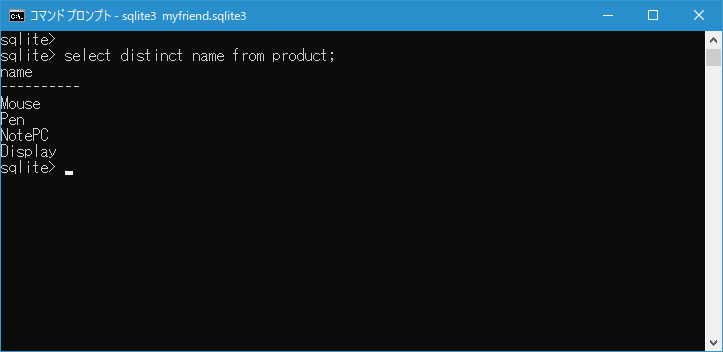
name カラムの値の中で重複した値を取り除いたデータを取得することができました。
次に同じように product テーブルの color カラムの値を DISTINCT キーワードを指定した場合としなかった場合でそれぞれ取得してみます。
select color from product;
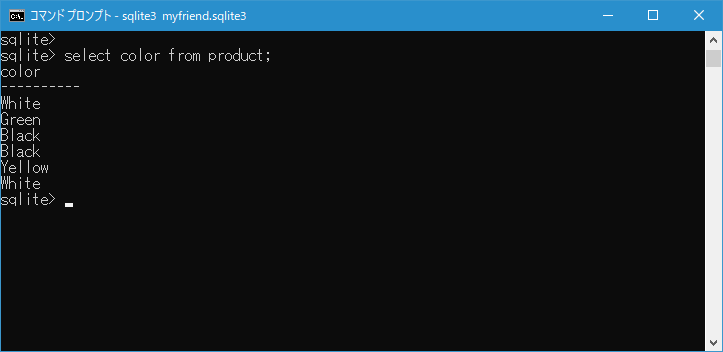
select distinct color from product;
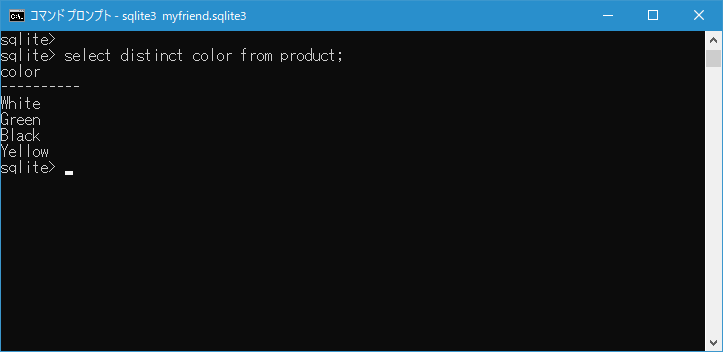
DISTINCT を指定することで color カラムの値の中で重複した値を取り除いたデータを取得することができました。
複数のカラムを対象に重複データを除外する
複数のカラムを対象に重複データを除外する場合は、複数のカラムの値の組み合わせが一致したデータを除外します。例えば先ほど使用した product テーブルで name カラムと color カラムのデータを取得する時に重複したデータを除外して取得する場合は次のように記述します。
select distinct name, color from product;
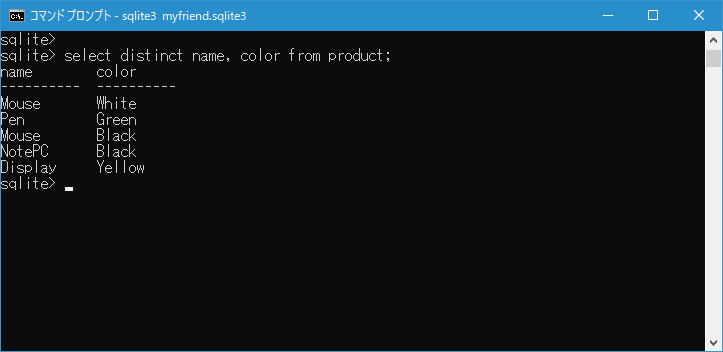
それぞれのカラムの値だけであれば同じ値があるデータもあるのですが、2つのカラムの値がどちらも同じデータは除外されています。
-- --
DISTINCT を指定することで重複したデータを除外してデータを取得する方法について解説しました。
( Written by Tatsuo Ikura )

著者 / TATSUO IKURA
これから IT 関連の知識を学ばれる方を対象に、色々な言語でのプログラミング方法や関連する技術、開発環境構築などに関する解説サイトを運営しています。